This article originally appeared in ;login: Online on Mar26/25.
The University of Michigan (U-M), founded in 1817, is the oldest institution of higher education in the state, with over 52,800 enrolled students, around 9,200 faculty and 47,900 staff, a main campus in Ann Arbor and two regional campuses in Dearborn and Flint, and a hospital system with many statewide general and specialty clinics. The College of Literature, Science, and the Arts (LSA) is the largest and most academically diverse of UM-Ann Arbor's 19 schools and colleges with approximately 22,000 students and 3,600 faculty and staff, making it larger than some other universities. LSA Technology Services (LSA TS) has about 180 full-time staff to manage all of the administrative and classroom technology in nearly 30 central campus buildings and several remote facilities both in and outside the state. The LSA TS Infrastructure & Security team had 13 staff and two managers who provide or coordinate over 70 foundational IT services for the college and the university.
The Infrastructure & Security team holds a monthly "Innovation Day" where we can focus on a specific project or service outside of our regular daily operations, and completely ignore chat, email, and tickets for the day. On our Innovation Days in February and March 2024 we ran tabletop exercises of some of our Disaster Recovery Plans (DRP).
Our team has had DRPs for at least our major customer-, patron-, or user-facing services since at least 2008 (the oldest template I could find), but we identified several problems:
Plan authors often worked in isolation and could have different assumptions than other authors, such as one assuming that scheduled tasks would be easily remembered or recovered, even if the system was upgraded. Furthermore, the original author of the plan was likely the service owner, service manager, or technical lead when it was first written... but staff turnover and service reassignments meant a different person became responsible for that plan and could have different assumptions than the previous owner.
Our web hosting environment service's DRP is an example of this: it was written/created by one person who left for another school, taken over by a second person who left for a different unit at the university, and is now owned by a third... whose tenure didn't overlap with the first. Each of the three likely had different assumptions and blind spots. For example, when the servers were upgraded the scheduled tasks that copied site archives to long-term storage and deleted them from local disk were themselves deleted, and nobody noticed until after the older OS backups expired.
We wanted all plan owners to:
To address writing plans the same way, in 2022 we standardized our DRP template and included embedded guidance about using it. Its major sections are:
Not all plans require all of that information. For example, the "Software" section might just be the operating system specification. You might not have, use, or need formal SLAs or SLEs.
Formal DRP tabletop exercises tend to have four roles:
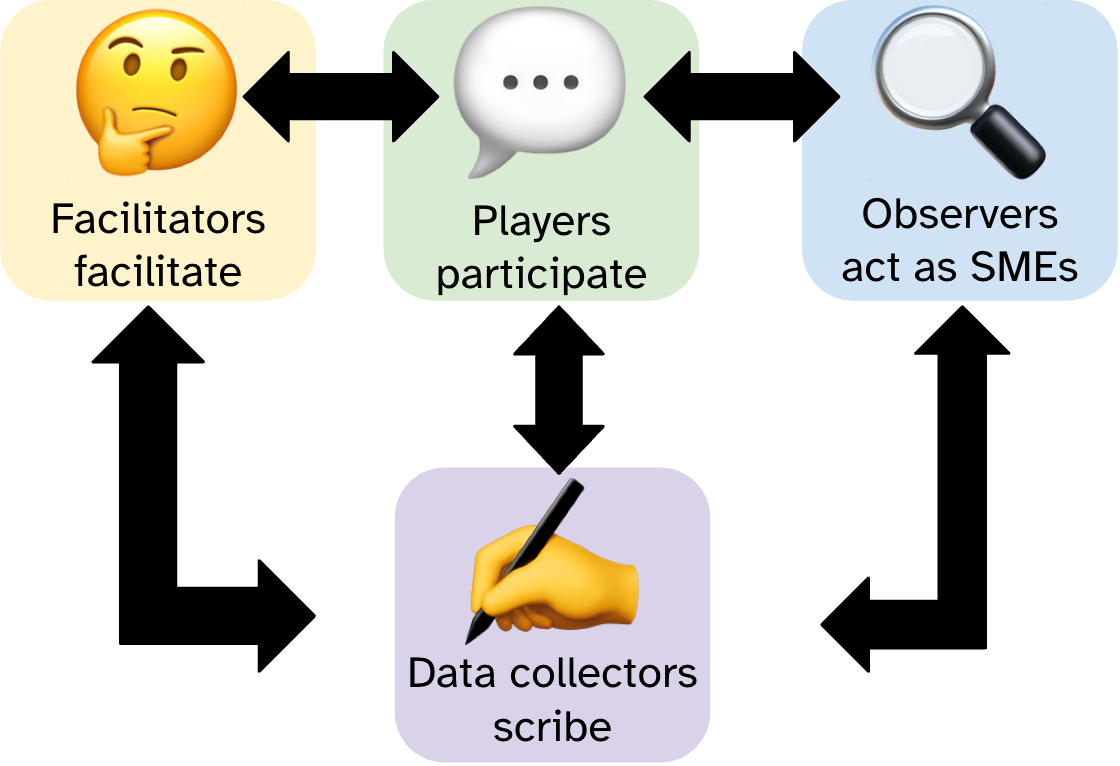
Figure
1: Diagram illustrating DRP exercise roles. Top left has a
"thinking face" emoji labeled "Facilitators facilitate;" connected
by double-headed arrows to top center with a "speech bubble" emoji
labeled "Players participate;" connected to top right with a
"magnifying glass" emoji labeled "Observers act as SMEs." All three
are connected with double-headed arrows to the bottom item, a
"writing hand" emoji labeled "Data collectors scribe."
We decided early in our planning process that we didn't need that level of formality during the exercise itself and combined the observer and data collector roles. Instead our team used two consecutive Innovation Days to run informal guided tabletop exercises to:
We tested three services' plans:
People in service management roles (the service manager, service owner, and technical leads) played as themselves. Others played as other parties, such as our own management, the Dean's Office, central IT's Identity and Access Management (IAM) team, the network team, and so on. We tried to get everyone to participate as a player at least once, and we asked 3–4 different people to act as observers and data collectors in each exercise.
However, we did not:
We postulated that an attacker got into one hypervisor node and thus the entire cluster and its storage, including every VM's disk image and their snapshots and backups. Had the event been real and if the attacker waited long enough for the external backup solution to expire its tapes, we would have had to rebuild the VM environment and every service on it from scratch without any trusted backups.
We hypothesized that an attacker gained root access to the web server for over 130 hosted websites. This was mitigated by host-unique root passwords, no ssh-as-root, and (unlike our VM environment) no on-host backups, so the attack surface was limited and recovery from backup was possible. If the event had been real we still would have had to rebuild the server, reinstall the hosting software, recover all the sites from backups, and change all of the websites' passwords, keys, and certificates.
We assumed that an attacker had gained physical access to our on-campus data center. Since we had time during the exercise we considered destruction, theft, and destruction to cover up theft. This was mitigated by having moved about 80% of our physical hardware to virtual hardware, our newer off-campus data center, or both.
We identified an interesting constraint that not everyone was aware of. One researcher's grant requires the server and its data to be in a specific locked rack, so we can't move it to another data center or to another rack in this data center. We also identified two open questions to answer after the session:
If the event had been real we have specific documented processes for what to do and who to contact in our Facilities, General Counsel, Plant Operations, and Risk Management offices, as appropriate depending on the nature of the event.
How did we define and measure whether these exercises were successful? First, we looked at our initial goals. We determined from the wrap-up discussions during each of the exercises that we did level-set our assumptions, dependencies, and expectations; improve our understanding of how we would actually implement our DRPs; consider what we may need to add to, change in, or remove from our environment (both the service and the organization); identify and fill any gaps in our DRPs; and identify any blind spots to remediate before our next disaster.
We also surveyed the participants after both days. We asked four questions:
After the second session we also asked if the first session was better, the second session was better, or if they were about the same.
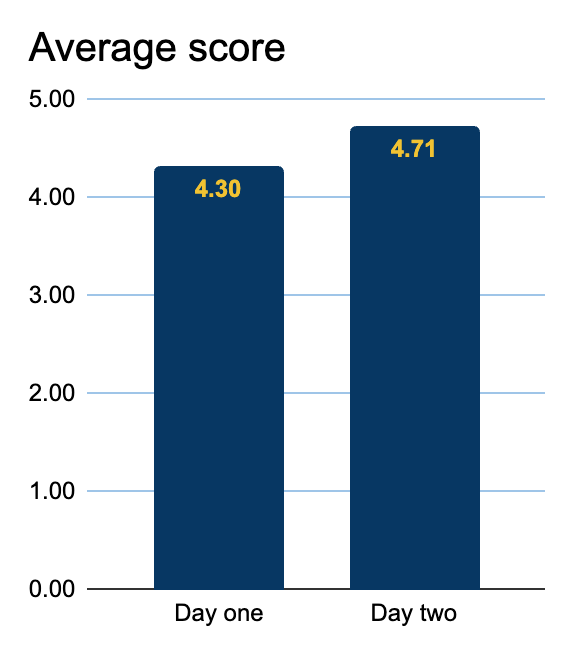
Figure 2: Feedback
survey results - numeric scores.
Our numeric scores were:
People thought that the first session was engaging. One respondent said they "learned quite a bit about DRPs and how we should handle things." A second respondent said "It was good to see the thought processes and priorities for each member of the team and the collaboration in solving problems (or creating them) as we worked our way through the virtual incident." A third said that "The opportunity to dig into some deep thoughts on some very multifaceted problems as an entire team was enormously helpful." Several felt the roundtable discussion was helpful and the session "worked out well as a brain-storming session" and "was helpful for those not involved in the operation of the service to understand the challenges it would experience during a disaster recovery procedure." People identified holes in their own plans, new things to think about, perspectives to change, and a deeper understanding of the service itself.
However, some thought that we got lost in the weeds a bit. One respondent said "It's easy to go down some pretty deep rabbit holes. There's a balance here, because those rabbit holes sometimes dig up value, and sometimes don't." Another respondent wanted the problem to get more clearly defined as we worked our way through the discussions. In addition, including our Major Incident (MI) communications and coordination process was an unnecessary complication. One person provided our favorite comment: "This exercise was terrifying."
We agreed with the feedback. For the second session we defined the initial problems more clearly and omitted the MI process.
After the second session people thought that the more-focused topics were easier to manage and the open discussion was still helpful. We focused more on technical actions than communication actions which was an improvement. However, some still thought we spent too much time going down rabbit holes and that the scope may have been too narrow for everyone to feel like they were contributing.
At the end of each session we identified next steps for both the participants and the facilitators. Participants were asked to update their services' plans to include the common dependencies and anything else the plans were missing. Those common dependencies that some people thought were "too obvious to list" included:
Participants were also asked to create missing or update existing architecture, build, or design documents, to implement any remaining takeaways from the discussion, and to reconsider restoration time versus the declared maximum acceptable downtime. For example, if it would take two days to get replacement hardware spun up and another four days to restore the data, then without access to a time machine the maximum acceptable downtime cannot be less than six days. If there's a disconnect then either the business unit has to accept a longer maximum acceptable downtime or they have to provide funding for the design, implementation, and operation of the service to meet their requirement of that shorter maximum acceptable downtime.
In the short term the facilitators would analyze the survey results and feedback, discuss them at subsequent team meetings, decide on a cadence for repeating the exercises (annually in February and March), and develop a training module and documentation templates to train additional facilitators. For the university they also reached out to the Disaster Recovery/Business Continuity Community of Practice leads about presenting our exercises and results.
If you're working on your own disaster recovery plans we have some recommendations for things you should consider.
When writing your plans:
When testing your plans:
We set out to revamp our DRPs and make them more useful: we wanted to explore a broader range of scenarios, find incomplete documentation and testing, and identify where team members held differing assumptions about our infrastructure capabilities and requirements. We examined three specific scenarios: virtual machine infrastructure compromise, web hosting environment breach, and on-campus data center intrusion. These exercises aimed to refine our DRPs by revealing weaknesses and improving the team's understanding of them# and terrified some team members. In short, we learned a lot, both about our systems and about running DRPs: who should be involved, how broad or narrow the focus should be, and how to structure the discussions. We also had a lot of productive conversations with each other and with the business units we serve.
Some resources that may be helpful if you're going to run your own tabletop exercises include:
Also useful is the Cybersecurity and Infrastructure Security Agency (CISA) Tabletop Exercise Package (CTEP), especially: